Great Data Products
This is an abridged version of a keynote given at the 2025 Chan Zuckerberg Initiative Open Science Meeting.

Photo provided by the Chan Zuckerberg Initiative.
I’m an English major. I have degrees in Spanish and English from the University of Utah and a master’s in foreign policy from UCSD. Despite my non-technical background, due to a series of accidents, I’ve managed to work in data sharing and science policy for almost two decades. And despite my technical career, I’m still a humanities guy at heart, and I’m convinced that the language we use to talk about data is keeping us from realizing its full potential.
As we contemplate the future of data sharing in 2025, it’s worth looking at how far we’ve come over the first quarter of the century. Here’s a cherry-picked set of technological and institutional innovations that have shaped my career:
- 2004: Facebook founded. First AWS service announced.
- 2006: Amazon S3 launched.
- 2007: iPhone launched. Common Crawl founded.
- 2008: GitHub founded.
- 2009: data.gov founded. Code for America founded.
- 2010: Open San Diego (among many other local civic tech nonprofits) founded.
- …
- 2025: DOGE founded. AWS Open Data program announces that over 300PB of data are freely available in S3.
The rise of the Internet in the first decade of the century was exhilarating. When I got my master’s in foreign policy in 2006, I was so excited about “Web 2.0” that I turned my back on everything I’d studied to take a job as a “marketing enthusiast” at a startup. This seemed like a very strange move at the time, but I’m happy with how it’s turned out. I learned how software and data work on the Internet, and it was a perfect opportunity to start shaping a career working at the intersection of the Internet and governance.
Twenty-five years in, that exhilaration has tipped over into… something else. The impact of the Internet has been astonishing, and it has quickly produced entirely new categories of winners while actively disrupting many institutions.
I try to maintain a stoic view of all this. The Internet is a very new thing, and we still haven’t learned exactly how to use it. This means we don’t have to accept the status quo. The Internet still holds tremendous potential to help us cooperate on global challenges, but it’s time to learn some difficult lessons from the century so far and shed some dogmas about data.
Magical thinking everywhere
For many years, open data enthusiasts like me have operated under the assumption that data is inherently valuable. Data is an unalloyed good and good things will happen if we make more of it open. This is sloppy thinking that has led us into a few dead ends.
Here are a few notable policies and declarations related to data sharing from the century so far:
- 2003: NIH declares that researchers who receive grants larger than $500K should share data with other researchers.
- 2005: The Open Definition drafted.
- 2007: 8 Principles of Open Government Data published.
- 2011: NSF requires researchers to submit data management plans with grant proposals.
- 2016: The FAIR Guiding Principles for scientific data management and stewardship published in Nature.
- 2019: The OPEN Government Data Act becomes US federal law.
- 2020: The CARE Principles for Indigenous Data Governance published in the Data Science Journal.
This is a history of us deciding that data should be shared and gradually figuring out who should do it and how to compel them to do it. Much of this work has been guided by the belief that “information wants to be free.” I use the word “belief” deliberately here.
It’s time to admit that wishcasting more open data into existence has not produced the results we want.

Anyone who’s worked on open data for any amount of time is not surprised by this. Most researchers and bureaucrats are already overburdened with requirements and guidance, and it’s always been naive to think that we could expect them to simply figure out how to share increasingly large volumes of data over the Internet. Data sharing mandates and policies have rarely come with the funding and services needed to be effective.

Magical thinking about data isn’t exclusive to the tech-for-good crowd either.
In 2017, The Economist declared that “data is the new oil” and countless people misunderstood the metaphor. The Economist had accurately noted that data had become the world’s most valuable resource and that governments needed to think about regulating the entities using data to accrue and wield power.
But what many people heard was that data could make you rich, spawning countless business models built on vague notions of being able to monetize just about any kind of data.
Unlike oil, data is not a fungible commodity – the value of data is extremely variable and hard to determine.
How do we get out of this?
Fix the noun. Talk about data products.
As an English major, my advice is to fix the noun.
Stop talking about “data” in the abstract. Talk about “data products” instead.
A data product is simply data you intend to share. Talking about data products forces practical questions: who uses it, how much it costs to produce, what value it delivers, and who will build and maintain it.
It shifts us from “just add an open license” to usability: Who will use it? Do the users need customer support? Is the data provided in a common format? Does it have metadata? Is it streamable? Realistically downloadable? Documented? Does it have an open license? Should it have an open license?
In short, talk about how the data actually works in practical terms, not how it should be.
The ideals of open or FAIR principles are nice, but they refer to attributes of data products that don’t address their substance. You can have perfectly FAIR, utterly useless data.
The next question is to figure out what a data product should look like.
This is what I call the “sweet spot” graph, which I’ve found useful to explain what data products should be like. The gist of it is that you’re not likely to reach many people if you distribute raw data in whatever format it’s produced, but you also don’t want to over-process your data or overdetermine how it’s presented. It costs money to create and maintain APIs, interfaces, and dashboards. Worse, they force interpretations onto the data that constrain its potential value.
The sweet spot is a place in between raw data and a dashboard or app designed for a specific use case. It usually requires making data reliably available for programmatic access, using commonly used formats, and with documentation. If you’re thoughtful about these things, people will be able to build whatever tools or analyses they want to on top of it.
A good example of how this approach has worked in practice is the history of the Cloud-Optimized GeoTIFF.
Fix the adjective. Move beyond “open.”
While it would be a good step forward to talk about “open data products” rather than merely “open data,” it’s time to admit that “open” has ceased to be a useful adjective.
“openness is today being used by companies as a rhetorical wand to lobby to entrench and bolster their positions”
The quote above is from a 2024 paper I helped edit titled “Open (For Business): Big Tech, Concentrated Power, and the Political Economy of Open AI”. I didn’t come up with the term “rhetorical wand,” but it’s a great way to describe the cynical ways that “open” has been rendered useless as a term.
But even before it was co-opted, “open” was already an imprecise and unhelpful adjective for the reasons described above. In 2023, we simply declared We Don’t Talk About Open Data because of its shortcomings.
Rather than declaring a data product “open,” we use this graph to examine the technical and ethical challenges to data sharing.
When considering technical challenges, we can ask: Are there widely used formats for this type of data? Is the data too big for most people to handle? Does this data require access to specialized software?
These technical challenges are often solved by market forces. Continual competition among IT service providers puts downward pressure on costs and upward pressure on performance. Ten years ago, it was very difficult to share a large relational database using flat files. Today, technologies like Parquet and DuckDB make this trivial.
Meanwhile, the ethical or “human” challenges can be much harder to solve. There are implications to increasing shared understanding of the world, particularly as we consider gathering and distributing data to inform policies to govern our environment, human health, and the global economy.
The openness of a data product should be informed by a nuanced understanding of these challenges.
Products cost money.
And to make sure you know I’m fully capable of heresy: thinking in terms of products forces us to recognize that information is not free no matter how much it might want to be. Economists Eli Fenichel and David Skelly from the Yale School of the Environment published an article in BioScience in 2015 with a perfect title: Why Should Data Be Free; Don’t You Get What You Pay For?
It’s incoherent to claim that data is extremely valuable and that it should somehow also be free. This doesn’t mean there aren’t reasons to subsidize data access to make it available at no cost, but it means we need to acknowledge the costs of producing, distributing, and governing data. It’s time to stop waving these realities away.
Great is better.
“Great” is a better adjective than “open.” Trust me. While “great” doesn’t have a precise meaning, it’s a usefully evocative adjective. We talk about great novels, great movies, great discoveries. We should start talking about great data products.
AlphaFold, ImageNet, MIMIC-III, Common Crawl, OpenStreetMap, CMIP, Xeno Canto, iNaturalist, ERA5, IRS 990, Landsat and 1000 Genomes are all great data products. You might not know all of these by name, but these data products have been the basis for education, new discoveries, new businesses, and at least one Nobel Prize. They’ve brought people together, enabled cooperation on huge challenges, and changed our lives.
What makes a data product great? This is a hard question to answer. It’s the same as asking “What makes a movie or a novel great?” Their greatness is a function of the impact that they have on the world, and we understand that making something great is hard. It requires vision, thoughtfulness, and understanding of one’s craft.
If it can work in practice, then it can work in theory.

Photo: U. Montan. ©The Nobel Foundation
This is Elinor Ostrom, matron saint of Radiant Earth, who won the Nobel Prize for Economics in 2009. She sought to understand how people around the world have managed to manage shared resources and avoid the tragedy of the commons. Her work is extremely relevant to data sharing. “If it can work in practice, then it can work in theory” can’t be directly attributed to her, but it captures her approach nicely and has become known as “Ostrom’s Law.”
We know that people have figured out how to create great data products in practice, so it’s time to do some metascience to understand how they did it.
The shape of data products

Cover of Extracts from an Investigation Into the Physical Properties of Books as They Are Presently Published
When we talk about great books, movies, and papers, we have the advantage of knowing more or less what the shape of those things are.
When you encounter a book, you can find a lot of metadata to help you tell if it’s worth your while or not. Books have titles, authors, covers, publishers, a price, and reviews.
Because books have been around for so long, we’ve developed social structures and conventions around them and have even found ways to pay people to be professional book reviewers. Above is the cover from a funny book written by “The Society of Calligraphers” about the declining quality of books from over a hundred years ago. You can read it on the Internet Archive.
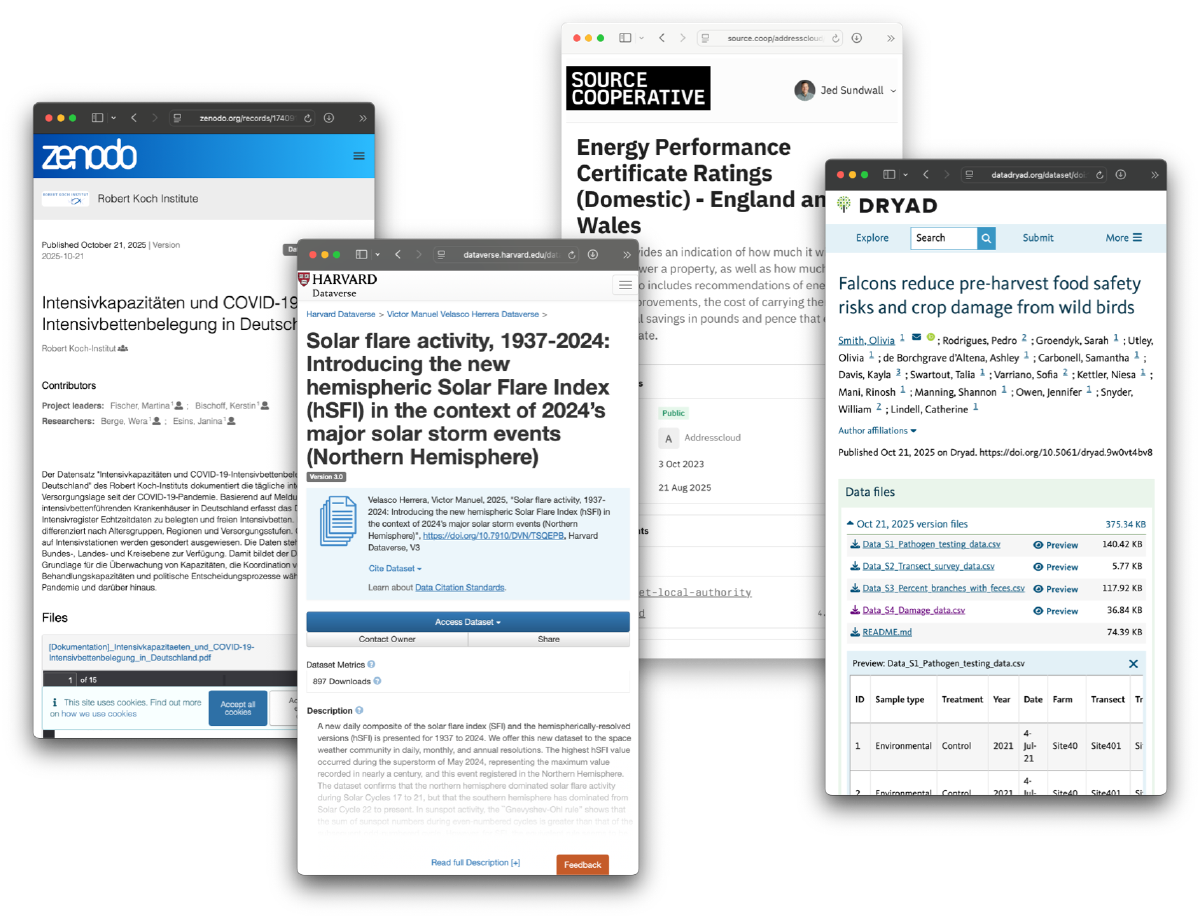
The good news is that we are developing an understanding of how to present data products to the world. A data product should live at a URL. It should have some files, some notion of provenance, documentation, a DOI, a commonly-used license, and metadata. Greatness is more likely to be attained if data publishers are thoughtful about all of those things.
But we need more forums and venues for data practitioners to talk with one another. This is already happening at plenty of academic conferences, but it’s not enough.
Creating the conditions for us to understand how to create great data products is a big part of our work at Radiant Earth. We see Source Cooperative as a canvas where data publishers can do their greatest work. The community of geospatial data experts we convene in the Cloud-Native Geospatial Forum are constantly working on ways to produce better data products for one another. We offer fiscal sponsorship for projects focused on creating novel data products.
We recently started a podcast called (shockingly) Great Data Products where we host honest conversations with data publishers about decisions they’ve made, what’s working, and what isn’t. The tagline for the podcast is: “A podcast about the ergonomics and craft of data.” As we produce more data at a continually increasing rate, we should be honest about the fact that we’re all feeling our way in the dark. We’ll be better off if we feel our way in the dark out loud.
Where do great data products live?
From Denise Hearn’s The Downsides of Democratizing Access
Another sloppy term touted both by commercial and public actors over the past few decades has been democratization. I’m one of many people who has seen the Internet as a benevolent democratizing force – something that can empower people. I still believe this to be true.
But by now it should be very obvious that a great way to lock people into a platform is by giving them new capabilities that they didn’t have before. If you create a platform that helps someone express themselves and reach more people, you now have some degree of control over that person. This has created enormously powerful platforms that have undeniably empowered people in some ways, but are not democratically governed at all.1
It’s high time that we start deliberately funding the production of great data products, but we need to find more cooperative approaches to funding and governing data that do not lock people into proprietary solutions and are less vulnerable to capture by financial or political interests.
New data institutions
I am very lucky to have been born into a world that had a NASA in it, along with a NOAA, NIH, CDC, and NSF. I’ve always taken those institutions for granted, and it’s been shocking this year to learn how vulnerable they are. One way to respond to the turbulence of this year is to find ways to protect the institutions we’ve inherited, and I’m glad many people are doing that.
But it’s important to remember that these institutions didn’t always exist. People had to work hard to create them, and another way to honor the people who gave us these institutions is to create new, better institutions that take full advantage of today’s technology.
Our approach with Source Cooperative is to create a cooperatively governed service built using open source code on top of commodity cloud object storage that accelerates adoption of non-proprietary data formats. We see Source Cooperative as a new kind of institution that can help people publish data. We want it to be complemented by new institutions like Catalyst Cooperative, Open Supply Hub, OpenStreetMap, Overture Maps Foundation, iNaturalist, and Common Crawl that can reliably produce and govern great data products.2
John Wilbanks made the call for a new institutional approach perfectly in a piece called Funding Strategies for Data-Intensive Science earlier this year:
Without a change in how we organize scientific research itself, we won’t be able to use [recent] developments in data generation and modeling at scale. Science is often organized around the laboratory, the principal investigator, and the publication, rather than data, software, and computational power. This approach creates different cultures between institutions and scientific disciplines, and affects their usage of computation, collaboration, and ability to scale.
To create institutions that can produce great data products, we need to recognize that maximizing the potential of data is much more than a mere engineering problem. It requires diverse roles and expertise, including people who work in policy, management, customer support, finance, education, and communication.
We’ve never had more access to information about our world – and never more tools to describe and interpret reality. But with that power comes the need to invest in cooperative governance models to create, manage, and share great data products. Only then can we ensure that new knowledge leads to a shared understanding of the world we’re creating.3
Thanks to Drew Breunig, Fernando Pérez, Millie Chapman, Denise Hearn, Lucas Joppa, Scott Loarie, and Marshall Moutenot for thoughtful feedback on drafts of this post. Special thanks to Dario Taraborelli and the entire Open Science Team at the Chan Zuckerberg Initiative for giving me the opportunity to speak at their meeting.
For more thoughts on the political economy of data, please read Internet Power ↩︎
For more thoughts on creating new data institutions, please read Unicorns, Show Ponies, and Gazelles ↩︎
This is self-plagiarized from “Emergent Standards”, a white paper I recently wrote for the Institutional Architecture Lab ↩︎