Exploiting Multi-Region Data Locality with Lambda@Edge
Last month I had the opportunity to present the architecture behind tiles.rdnt.io: Customer Showcase: Exploiting Multi-Region Data Locality with Lambda@Edge – AWS Online Tech Talks.
The webinar walks through the architecture and applications of Lambda@Edge and tiles.rdnt.io, which are summarized in this post. You can also watch the webinar video. If you’re not one for watching videos, you can flip through the slides with less context.)
tiles.rdnt.io is interesting for a few reasons: 1) it dynamically renders map tiles for imagery sources anywhere on the internet, 2) it’s entirely serverless – the tiler itself is implemented as a Python Lambda function, and 3) it’s replicated worldwide to reduce latency when rendering and network egress costs for imagery providers.
All together, these capabilities fundamentally change users’ relationships to imagery catalogs: there’s no longer a need to download full images (which can individually be multiple gigabytes) when partial areas are desired (see the Cloud-Optimized GeoTIFF for more info). For imagery providers, it’s no longer necessary to provision for maximal load; the number of Lambda functions will automatically scale to meet demand (expenses will scale up and down accordingly).
Network hops before and after incorporating Lambda@Edge
During the tech talk, Vijay Potharla (a Senior Project Manager on the CloudFront team @ AWS) and I walked through some of the capabilities that Lambda@Edge introduces to CloudFront and how Radiant Earth uses them to enable high-performance browsing of publicly-available imagery.
Lambda@Edge
For those unfamiliar with it, Lambda@Edge takes AWS Lambda’s compute model (serverless functions that respond to event triggers, billed by the 100ms), strips down some of its capabilities (functions are JavaScript-only and must complete within a shorter time window), and deploys it across CloudFront’s vast network around the world.
In this mode, functions at the edge of the network are empowered in a variety of ways with very low latency to users. Responses can be generated dynamically, previously-cached content can be manipulated on the fly, and decisions can be made to forward requests to specific origins.
Dynamically choosing origins is typically used for scenarios like A/B testing. Similarly (and more generally), content delivery networks (CDNs) are typically used to minimize request latency.
How Lambda@Edge makes tiles.rdnt.io better
Enhancing tiles.rdnt.io with Lambda@Edge has brought both you and the Radiant Earth Foundation a number of benefits:
- Rich tooling as a tangible benefit of adopting a standardized format (Cloud Optimized GeoTIFFs)
- Ability to browse multi-petabyte archives easily (e.g. those in the Registry of Open Data on AWS) interactively, and quickly
- Affordable for you: the service is free!
- Affordable for Radiant Earth: imagery is free or cheap (when using Requester Pays) to access, the infrastructure costs nothing when not in use (as it’s implemented as a Lambda function)
- Affordable for imagery providers: data transfer costs are minimized
tiles.rdnt.io is an odd duck, as its purpose (check out the introduction) is to enable interactive browsing of Cloud-Optimized GeoTIFFs that are much larger than one would typically want to download. It serves as a tile endpoint that’s able to slice up imagery from anywhere on the internet. This means that the ultimate “origin” of a given tile request can be anywhere in the world (often in an S3 bucket).
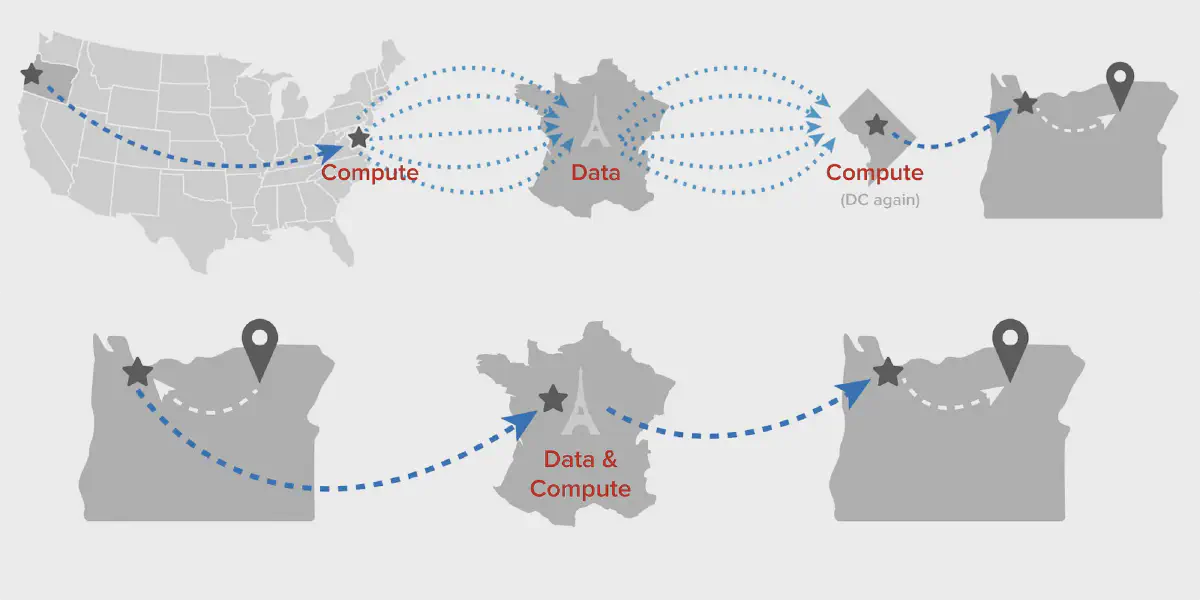
However, a standard CDN configuration places the tile server (the compute) in a central location, potentially far from the imagery being processed (the data). Add in the requisite user and we’re dealing with 3 locations. 4, if you count the CloudFront point of presence, which is intended to be as close to the user as possible.
For a hypothetical image in a Parisian S3 bucket, with a tile server in Washington, DC, and a user in Oregon, the data flow looks like this:
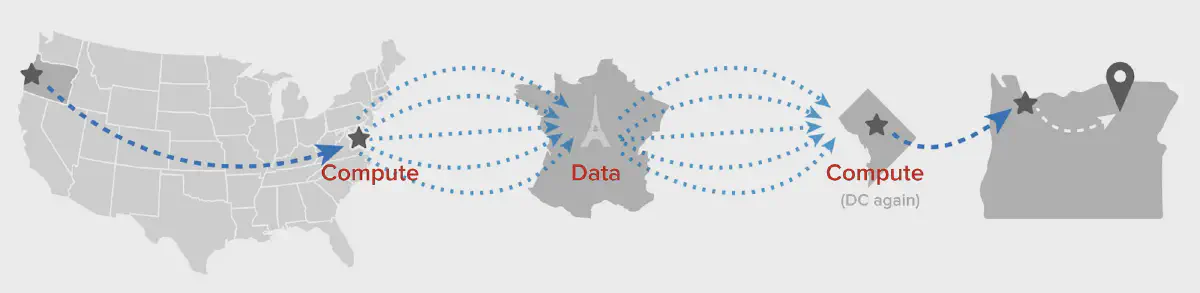
See all of those trans-Atlantic requests represented above? Those cost time (c is a hard limit) and money (cross-region data transfer isn’t free).
Wouldn’t it be great if there a way to shorten distances and reduce costs at the same time?
There is! Lambda@Edge’s ability to respond to “origin events” and provide request-specific origins gives us a way. Assuming we distribute the compute across multiple AWS regions, as we have with the API Gateways and Lambda functions that power tiles.rdnt.io, we can check the location of the source image and redirect to an appropriate API Gateway in the nearest available region.
If we take the same hypothetical image above and apply some Lambda@Edge magic, the diagram now looks like this:
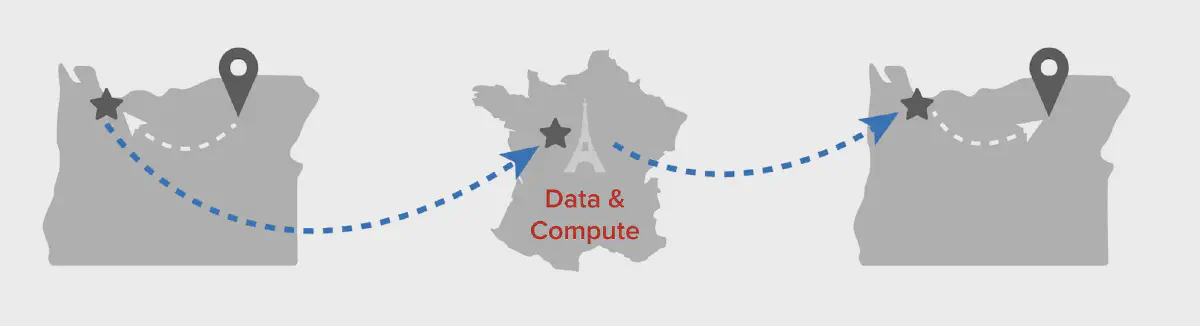
Not only have we co-located compute and data (data locality!), but we’ve also removed infrastructure in one region from the equation. We haven’t actually eliminated the hop between compute and data, but processing occurs locally in Paris now. The total distance for photons and electrons to travel has been substantially reduced (no more trans-Atlantic back-and-forth) and network egress ($$$) is now limited to the generated tiles, where it had previously included the data being processed.
(tiles.rdnt.io is distinct from most services in that it’s location-agnostic to the data being processed. However, if an organization’s compute and data are distributed across multiple regions, similarities may apply.)
I also talked a bit about cloud-optimized file formats and their benefits, which I won’t summarize here. However, for those old-skool ZIP enthusiasts, here are some musings on using them for archives of tiles.
Nuts and Bolts
Architecturally, this looks like the following, replicated across AWS regions which might host data that we want to process (for us, all of them):
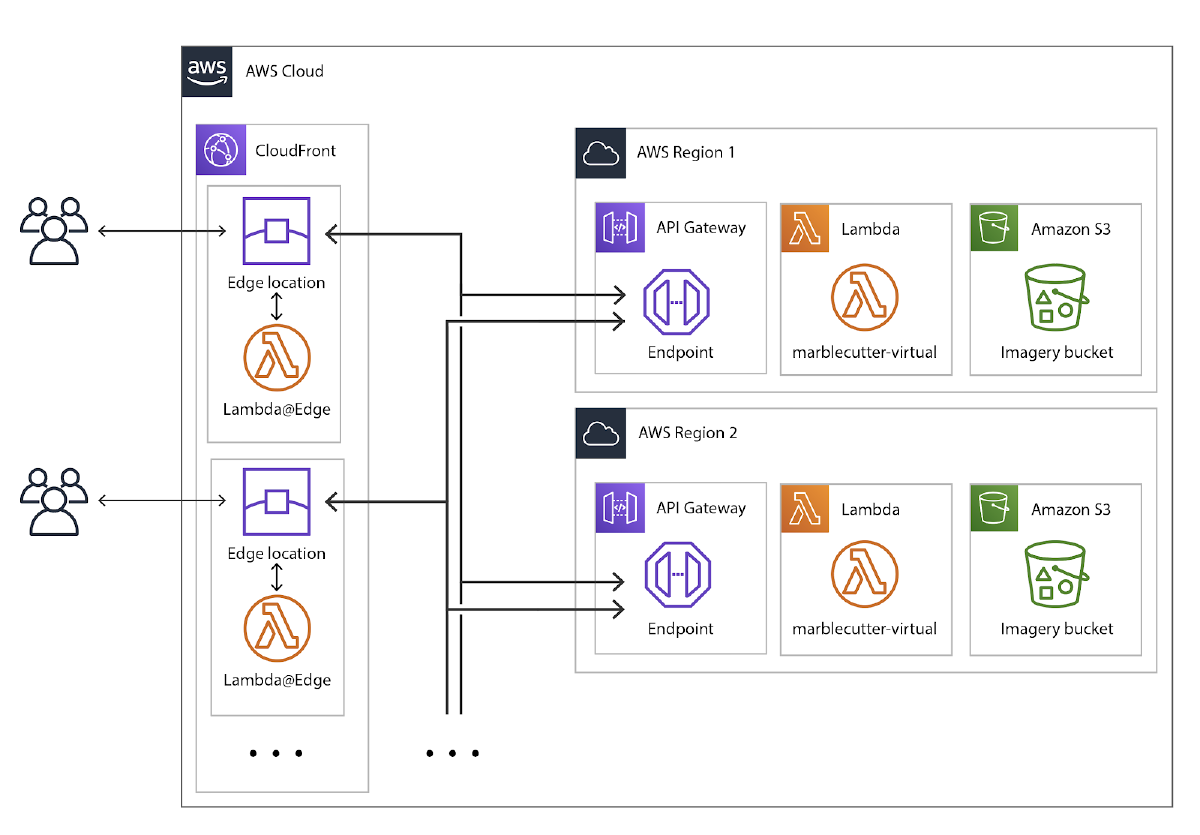
Deployment-wise, this is handled using the SAM (Serverless Application Model) CLI, which publishes CloudFormation stacks (managing API Gateways and Lambda functions) for each region that we target. Instructions for marblecutter-virtual (which is tiles.rdnt.io) are here.
On the Lambda@Edge side of things, there’s an origin event handler that extracts the image’s URL from the request, looks up the AWS region hosting its S3 bucket (if appropriate), and rewrites the CloudFront origin request to point to the correct region.
In the case of a NAIP scene, an individual tile URL looks like this:
The target URL’s bucket is extracted thusly:
The Lambda@Edge function that does all of this looks approximately like this:
And that’s all there is to it!

A NAIP scene. Dallas County | Scale 1:29000 (credit).