Democratizing Open Machine Learning Technologies for Earth Observation
I had the privilege of speaking at the closing plenary at the Pecora conference last month. The session’s theme was “The Next 50 Years: Synergy and Collaboration.” It gave me a chance to reflect on my experiences within the Earth science community and our plans for the future of Radiant Earth.
Inspired by the wonderful presentations Paul Ramsey has given over the years, this post attempts to create a readable version of my presentation at Pecora. It is the first in an ongoing series on our approach to create a more sustainable ecosystem of open machine learning and Earth science community.
What is democratization?
Democratizations don’t happen by themselves. They need inventions.
The quote above is from Jane Jacobs’s book Systems of Survival. Jacobs is a hero of mine. If you don’t know who she is, do yourself a favor and look into her. She was a social theorist and writer most famous for writing a book called The Death and Life of Great American Cities. Democratization — which I define roughly as giving more individuals more power — has been a consistent theme of my career for the past 20 years, and what Jacobs says about it rings true to me.
Let’s use her observation about democratizations to consider some inventions that have empowered individuals. To encourage democratic governance, humans have created things like constitutions, voting processes, ballots, and political parties. Beyond governing systems, individuals have been empowered by a very long list of inventions such as written language, the printing press, libraries, public companies, the Internet, online marketplaces, public cloud, and social media.
I often encounter the belief that openness is synonymous with democratization; that is, if you make data or software openly available, you can say you’ve democratized it. I don’t think that’s true. The Earth science community has benefited tremendously from open access to Earth science data, and I look forward to a future that features much more open data. However, it’s worth considering the complementary inventions necessary to make open data useful. To put a finer point on it: making data open is necessary but not sufficient to democratize access to data.
But first, let’s talk about why this matters.
Ultimately, we at Radiant want to ensure that Earth observation data can be used to inform better decision making at all levels of society.
Maurice Borgeaud, from the Earth Observation Directorate at the European Space Agency, also spoke in the plenary. He was careful to point out that the Copernicus program was not designed for scientists but to support European Union policy objectives. That is, Copernicus exists to improve the quality of governance in Europe as determined by the European Union’s democratic decision making processes. The point of the Copernicus program is not simply to enable science and to hope that good things come out of it. Rather, the Copernicus program enables science specifically to improve the quality of governance in Europe.
An extremely simplistic model to show how data can inform policy making might look like this: Gather data → learn things from the data → use new learnings to inform policy → see if the policy is effective → repeat.
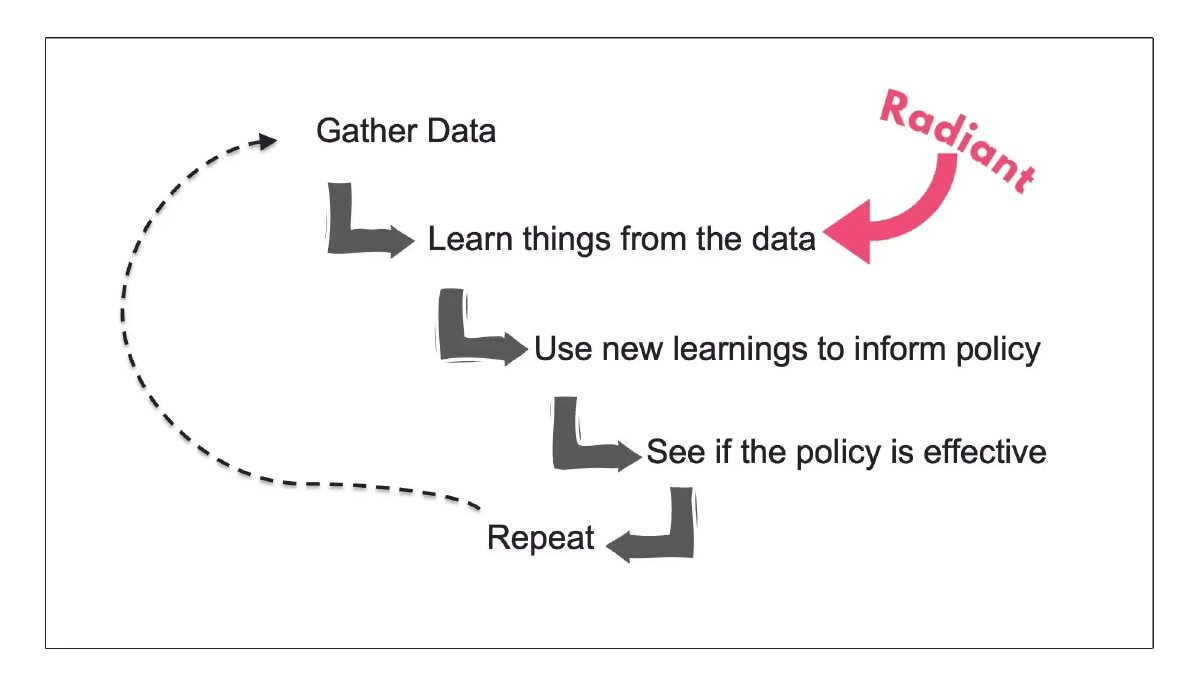
Radiant helps with the second step in that model: Learning things from Earth observation data. In particular, we focus on supporting open machine learning technologies that dramatically reduce the time and cost of analyzing Earth observation data. Doing this requires a lot of trial and error. Also, because we focus on, um, the entire planet, we need to consider the needs of everyone on Earth. This then requires serving the most diverse audience possible. In short, we work on democratization because we need all the help we can get.
So, what inventions do we need to empower more people to work with machine learning tools and Earth observation data?
Let’s look at one relatively recent Earth observation invention I’m familiar with: the Cloud-optimized GeoTIFF (COG).
Back in 2014, thanks to a tip from Chris Holmes, I started looking into making Landsat data available on the AWS cloud. One of the first things I discovered was that people got Landsat data from USGS by downloading gigabyte-sized TAR files that contained 12 TIFF files, but most users only ever used about 3 of the TIFFs. It was immediately apparent that we could save people a ton of time by letting them access data on a per-TIFF basis from Amazon S3 instead of an TAR file. Together with many generous people (including Frank Warmerdam at Planet, Peter Becker at Esri, and Charlie Loyd and Chris Herwig at Mapbox), we took this idea even further and added internal tiling to the TIFF and launched what we called Landsat on AWS. This allowed people to not only access only the TIFFs they wanted, but allowed them to access specific tiles within the TIFFs they wanted. Not only did this save time, but it also let people build apps that could interact with a massive corpus of Landsat data in real time. Thanks to the work of many people in the geospatial data community, this approach has since evolved into a widely-used best practice called the Cloud-optimized GeoTIFF (COG).
I’ll dive deeper into the history of the COG in a future blog post, but I bring it up here to point out that it was not easy to see the COG as an “invention” at the time that we launched Landsat on AWS. We simply wanted to make it easier for people to access Landsat data, and we found a way to do that which took advantage of a number of pre-existing inventions. To name a few of them:
- Landsat, an incredible high-quality planetary-scale data product that was made openly available by USGS;
- The World Wide Web and the Hypertext Transfer Protocol (HTTP), which enables range requests;
- The Geospatial Data Abstraction Library (GDAL), an open-source library used to create COGs and read them efficiently;
- Cloud-based object storage; and
- A public cloud business model that enabled AWS to host large volumes of open data at no cost.
When you look closely at past inventions, you will find that most of them are emergent — they arise out of many interacting things. As we look toward the future, we have to think not just about about singular inventions, but the multiple inventions that will interact to create the outcomes we want.
Now again: what inventions do we need so that Earth observation data can be used to inform better decision making at all levels of society?
We need a lot of things, but here are three that we focus on: new data products, new scientists and leaders, and new kinds of institutions.
New data products
Training machine learning models requires a lot of data. We live in a golden age of Earth observation data, but enormous work remains to create training data to power ML models that can interpret all this data. If you’ve marveled at the recent breakthroughs made by Dall-E or Stable Diffusion, you should know that the methods used to create those models have been developed over many years by researchers with access to widely-used and well-documented training data products like ImageNet, COCO, and LSUN. The autonomous driving community benefits from their own bespoke open training data products. The research we need won’t happen if we don’t first create more novel training data products specifically for Earth observation data.
Creating accurate annotated Earth observation data is expensive. It requires a lot: human labor, the development of new software and devices that can be used to reliably gather ground truth data, the creation of new community standards to share complex data that is sufficient for scientific research, and thoughtful consideration of ethics (e.g., is it appropriate to share data about smallholder farms that represent the entire livelihood of families?).
I’m incredibly proud that Radiant has supported the creation of novel products like LandCoverNet (yes, its name is inspired by ImageNet) and the Replicable AI for Microplanning (Ramp) training dataset. These are incredibly ambitious projects that would have been unimaginable years ago. I’m confident that these training data products will accelerate research for years to come, but we need to create more products like them.
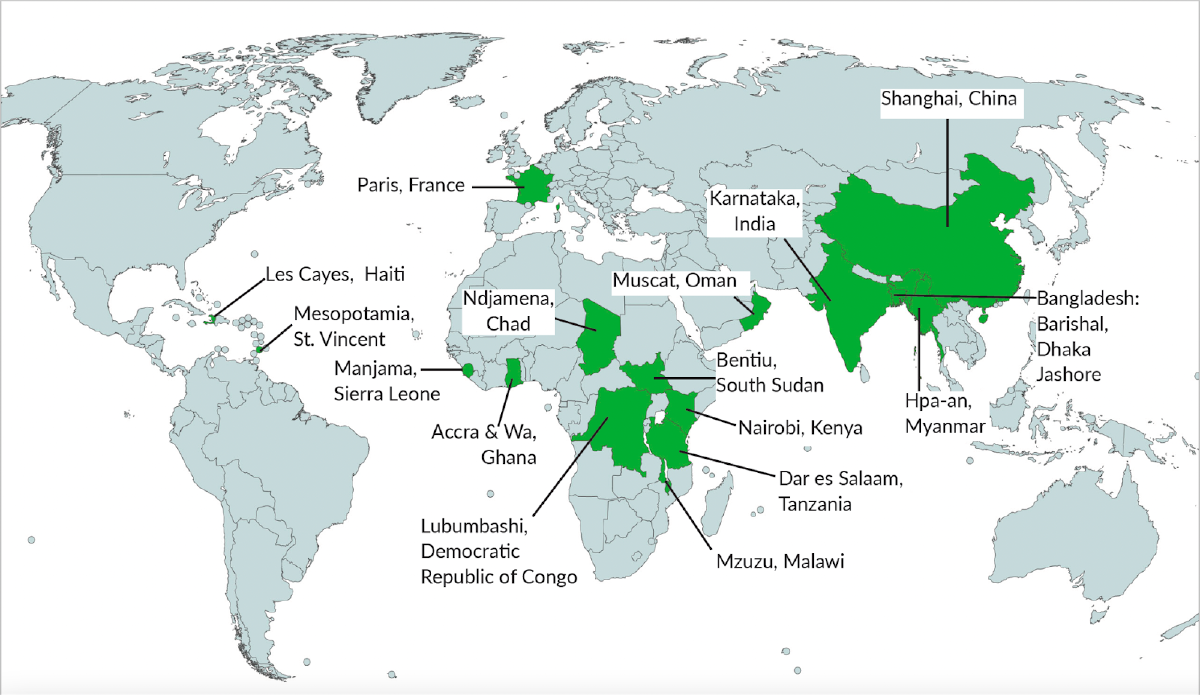
The Ramp open buildings model training data products include 1,298,610 labeled buildings across 17 countries.
New scientists and leaders
This might sound strange, but we need to invent new kinds of scientists and leaders around the world who can contribute to our work. We should find collaborators in places that the Earth science community has traditionally not reached out to.
LandCoverNet or Ramp would not exist without the support of B.O.T. (Bridge. Outsource. Transform), an impact-sourcing platform that provides high-quality digital services executed by skilled freelancers from marginalized communities in Lebanon. We worked with B.O.T., TaQadam (a mobile annotation platform), and Sentinel Hub to train over 100 freelancers in Lebanon to create human annotations of imagery for these data products. We see a tremendous opportunity to expand new skilled jobs in low- and middle-income countries. We simply cannot generate the data products needed for open machine learning science if we do not train a new cohort of skilled workers to do this work.
COGs have enabled the creation of browser-based interfaces that allow people to interact with Earth observation data by simply opening up a website. This creates an opportunity to insert Earth observation data into learning curricula for many more children worldwide. At Pecora, I talked with Dr. Rebecca Dodge who works at AmericaView, a nonprofit that seeks to insert Earth observation data into K-12 curricula. As we continue our work to make Earth observation data more accessible, we need to be deliberate about making it accessible to young students.
Years ago, I did a lot of consulting on government social media strategy, and I was inspired by Veronica McGregor, who ran the Twitter account for the Mars Curiosity Rover. She told me that a significant element of NASA’s mission is to motivate interest in science, and that their goal with Twitter was to inspire more people to “go outside and look up.” Veronica and many of her colleagues trace their science career to a moment of awe and wonder when looking up at the night sky. I’ll argue that we can also inspire careers in science by inspiring people to look down too.
We should use open Earth observation data in educational materials that teach kids how to code, learn about machine learning, and build apps. If we’re really lucky, we can raise a new generation of Earth scientists, and if we’re merely lucky, we’ll have created some compelling STEM educational content. No matter what, we’ll do our part to help more people understand the value of Earth science.

Let’s get more eyes on this thing. Earthrise, the iconic image of our home taken from Apollo 8 on 24 December 1968. Image credit: NASA.
New kinds of institutions
Certain kinds of organizations produce certain kinds of things.
One of the things that I loved about working at AWS was that so many kinds of organizations used AWS. We were deliberate about getting a diverse group of users to work on the data we hosted in the AWS Open Data Program. When I say “diverse,” I mean it in every possible way — and particularly in terms of budget. Really cool things started to happen when we got small, scrappy academic research teams in the same room as beltway bandits with money to burn. Everyone was able to learn from one another.
But one conclusion I’ve come to is that we need institutions designed from the ground up to support open science. This realization was a significant motivating factor for me to join Radiant.
We still live in a dichotomy where the government is asked to make data for free, or the commercial sector is expected to provide data by monetizing it. There is a lot of room for innovation between those two ends.
We’ve seen that the Internet can create compelling, powerful platforms that can reshape society. Imagine a scenario in which someone invents a novel social media platform that comes to exert enormous influence over global media and public discourse, to the point of having a major impact on democratic systems. Now imagine if an eccentric billionaire decides that he wants to buy that platform. If the billionaire’s offer is high enough, the board of directors of the platform will likely determine that it is their fiduciary duty to accept the billionaire’s offer. Now imagine what might happen if the billionaire started to exert his influence on the content of that platform.
(I recognize the irony that I hope many people Tweet about this post.)
I’m not here to make any normative statements about billionaires owning media outlets, but I will assert that it’s worth thinking what kinds of institutions we need to enable global coordination across all sectors. If we want to build something durable and reliable, we need to be very thoughtful about ownership structure and governance.
Geoff Mulgan stated this well in a paper he published about a new discipline called “Organisational architecture”:
At a global level, there is a striking lack of institutions well-fitted to the big tasks of our times, from carbon reduction to cybersecurity, data to post-conflict reconstruction.
I’m interested in exploring new ownership structures and business models that can support our ability to do what we do in the open over the long term. The data and the algorithms we create at Radiant are intended to inform policy that affects the entire planet’s population, and we cannot afford to produce those things in a black box.
I describe Radiant Earth as a “global nonprofit technology company.” We are indeed a sophisticated global technology company, but we are also incorporated in the US as a 501(c)(3) nonprofit organization which means that no one can buy us if they wanted to — no one can own a 501(c)(3). Many of us interact with nonprofit technology companies every day, such as the Bluetooth Special Interest Group, the Wi-Fi Alliance, or the USB Implementers Forum. Nonprofit technology companies are an indispensable part of the global technology ecosystem, and I think we need more of them focused on data sharing to enable global collaborative research.
If you’re interested in helping us create new data products, new scientists, new leaders, and a new kind of institution, we’d love to hear from you: hello@radiant.earth.