What is Source Cooperative?
A lot has happened since we announced Source Cooperative in May. This post is an attempt to describe what Source is and why we’re building it.
In June, we officially opened up Source to beta testers and we received an incredible response with interest from research institutions, businesses, and governments from around the world. We’re now hosting data products published by Maxar, VIDA, Streambatch, the Ecological Forecasting Initiative, the Clark University Center for Geospatial Analytics, and Protomaps. Chris Holmes, a Radiant technical fellow, has published a number of data products that make use of cloud-native geospatial formats. We have also finished migrating all data that was previously available on Radiant MLHub to Source Cooperative.
Developers are already using data hosted in Source to produce demos and tutorials, such as this serverless tool to explore Overture Maps data in the browser from Youssef Harby, this mashup of building footprint data with FEMA flood hazards from Postholer, and this tutorial from VIDA showing how to use DuckDB to explore over 2.5 billion building footprints.
What Source Does For Data Providers
One of the core beliefs behind Source is that it should be much easier for people and organizations to share data on the open web.
Source allows data providers to publish data on the web without needing to run their own server, create a data portal, an API, or a dashboard. In plain English, this means we allow people to upload files to a repository in Source and then get a URL that they can share with other people. This is what a repository looks like on Source:
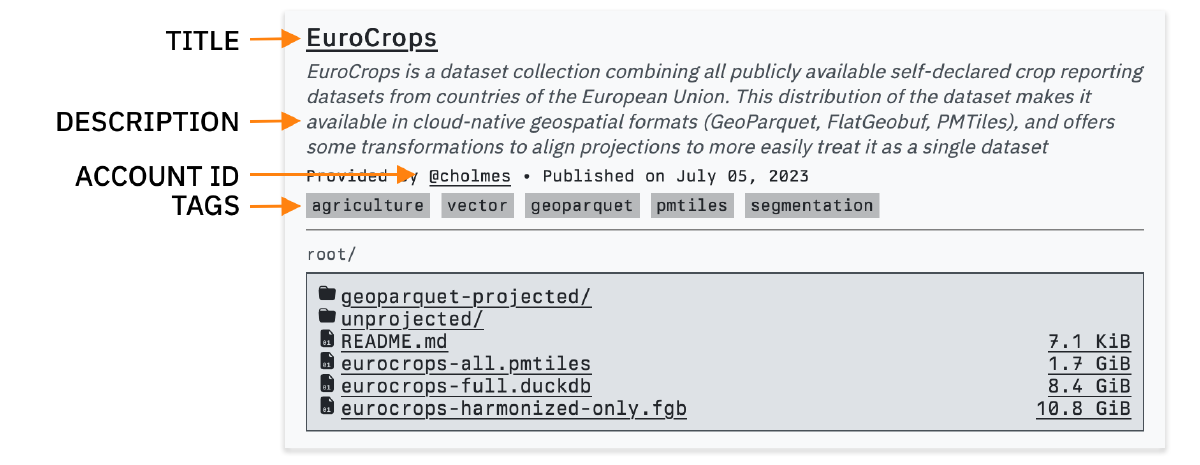
Each repository has:
- A human readable name (required): EuroCrops
- A brief description (optional): “EuroCrops is a dataset collection combining…”
- Tags (optional):
agriculture,vector,geoparquet,pmtiles,segmentation - An account ID (required):
cholmes - A repository ID (required):
eurocrops
The account ID and repository ID are used to create the URL of the repository. In this case, it’s https://beta.source.coop/cholmes/eurocrops.
Data publishers can upload whatever files they want into a repository and data users will be able to access those files on Source. If data publishers put a README.md file at the root of their repository, it will show up on the “Read Me” tab of the repository.
If you’re familiar with GitHub, this pattern of sharing files in a repository with a README file might seem very familiar, but the big difference between Source and GitHub is that Source is built entirely on cloud object storage as opposed to a file storage system which is required by Git. Using object storage allows us to host very large volumes of data. While a GitHub repository can host up to 5GB of data, we can host anything that our members can fit into a cloud object storage service. For example, the RapidAI4EO dataset on Source is over 100TB. The tradeoff here is that Source is not designed to provide anything like the distributed version control that Git enables. Source is not designed to manage granular version control, but is instead built to allow data providers to publish “fully baked” data products.
If you’re interested in learning more about the differences between object storage and file storage, this article from RedHat provides a good summary.
Competition among cloud providers has made object storage a very cost efficient and flexible way to share any kind of data. If a person or organization has a data product that they want to share, we want to make it easy for them to create a Source repository and put it on the open web. Source repositories include documentation, information about who provided the data, are easily sharable with simple human-readable URLs, and will be search engine optimized to improve data discoverability.
We also believe that data providers should never feel locked in to Source and are inspired by what 2i2c calls the Community Right to Replicate. If data providers want to move their data out of Source and host it elsewhere, they will always be free to do so.
What Source Does For Data Users
Source makes it easy for data users to access data the same way they access anything else on the web. As shown above, Source repositories all have a simple file browser interface that allows people to click around and explore. One way we like to think about it is as the Finder for data on the web. Everything in Source is designed to be linkable. For example, using the Eurocrops example from above, the URL for the root of the repository is https://beta.source.coop/cholmes/eurocrops/, but you can go deeper into the repository at a URL like this https://beta.source.coop/cholmes/eurocrops/unprojected/geoparquet/
But there’s more. Source has a “web” view and a “json” view. If you replace the beta at the beginning of those URLs with data, you’ll get a json blob describing the files and directories available at that URL. For example, going to https://data.source.coop/cholmes/eurocrops/ will give you:
{
"prefixes": [
"geoparquet-projected/",
"unprojected/"
],
"objects": [
{
"name": "README.md",
"url": "https://data.source.coop/cholmes/eurocrops/README.md",
"size": 7311
},
{
"name": "eurocrops-all.pmtiles",
"url": "https://data.source.coop/cholmes/eurocrops/eurocrops-all.pmtiles",
"size": 1877163857
},
{
"name": "eurocrops-full.duckdb",
"url": "https://data.source.coop/cholmes/eurocrops/eurocrops-full.duckdb",
"size": 9041358848
},
{
"name": "eurocrops-harmonized-only.fgb",
"url": "https://data.source.coop/cholmes/eurocrops/eurocrops-harmonized-only.fgb",
"size": 11637340312
}
],
"next": null
}
This allows users to programmatically access repositories, enabling the creation of scripts, applications, and reusable code that can refer to data from anywhere in the world. Our hope is that this feature will make it easy for more people to start learning how to code and work with data.
Source also allows users to access data directly from the cloud. Every repository has an Access Data tab where authenticated users can generate access credentials to get data directly from the cloud where it’s hosted. This is useful for users who want to bring their compute to data in the cloud. This enables them to build cloud-based applications, as well as perform large scale analysis using scalable cloud computing resources.
Our Business Model
Another core belief behind Source is that no single entity should own the systems required to share information necessary to solve global challenges such as climate change. As a non-profit, no one can own equity in Radiant Earth or any of our initiatives. This limits our ability to raise money on capital markets, but it also allows us to build a service that doesn’t lock customers into proprietary data formats, need to grow arbitrarily, or seek to be acquired. Our goal is provide a service worth paying for that can be financially self-sustaining.
We are not charging for Source while in beta. Thanks to support from the AWS Open Data Sponsorship Program and Microsoft’s Planetary Computer, we are able to host open data for free.
When we emerge from beta, we will continue to offer our customers a free tier for some to-be-determined volume of open data, but we will also start charging data providers a flat monthly or yearly fee based on the volume of data they need to publish. Our costs will likely be a premium on top of cloud object storage, which will allow us to absorb the variable data transfer costs we will incur.
We also anticipate charging some data users for data transfer. Our goal will always be to make sure that open data is “free for humans.” Browser-based human-computer interaction has a number of inherent limitations on how much data can be transferred at any time (e.g., time required to point and click while browsing an interface, the memory capacity of the browser, an individual’s ability to scan and absorb information). It will be our job to estimate the volume of bandwidth required to support this kind of exploration on Source. If we detect activity from bots or applications written to access large volumes of data, we will throttle their access and require authentication. At this point, data users will be able to access the data directly in the cloud (data will be hosted in Requester Pays buckets) or they will be able to purchase more bandwidth to access data over HTTP.
We have more work to do to get pricing right, but we are guided by these tenets:
- Users should pay based on how much they use. The best way for us to charge people fairly is based on how much data they can produce or consume. If you’re capable of producing or consuming a 100TB dataset, then you should be able to pay your fair share for data storage or bandwidth.
- Users shouldn’t have to guess how much they’re going to pay. Another term for cloud computing is “utility computing.” The vision of utility computing is that users will pay precisely for what they consume and no more. This extremely efficient approach to providing compute resources has enabled the creation of new business models and applications, but it puts the cloud out of reach for many organizations with inflexible or limited budgets. We plan to charge a margin on top of our cloud computing costs so that we can offer flat and predictable fees to our customers. Because we are a non-profit, any profits that we earn will be used to further our mission of improving access to data.
- We shouldn’t seek rents on bandwidth costs. While we believe that data users should pay their fair share of bandwidth, we do not want to put ourselves in a situation where we depend on revenue from data access. Users should be able to access data for free, at cost via a cloud provider, or through us for a reasonable fee.
While we are not yet formally structured as a cooperative, we will likely adopt the model of a utility cooperative that seeks to provide the best service to its members at the lowest possible cost. Data providers who pay to publish data on Source as well as users who pay for bandwidth will be recognized as members of the cooperative.
Our Roadmap
Another theoretical advantage of building software as a non-profit is that we can imagine a future in which Source is finished and further development will be focused merely on improving performance and security of our services rather than adding new features to drive growth. Until then, we’re focused on the following features:
Search
Users should be able to search for repositories by keyword. (Update: we added basic keyword search to Source on 16 Oct 2023) Over time, we will be able to add the ability to search for repositories based on metadata, but our first priority to enable search by keyword.
Upload data through the browser
Currently, the only way to upload data to Source is to use the AWS Command Line Interface. To the extent possible, we want to allow our members to upload data into Source through the browser.
File viewers with object-level metadata
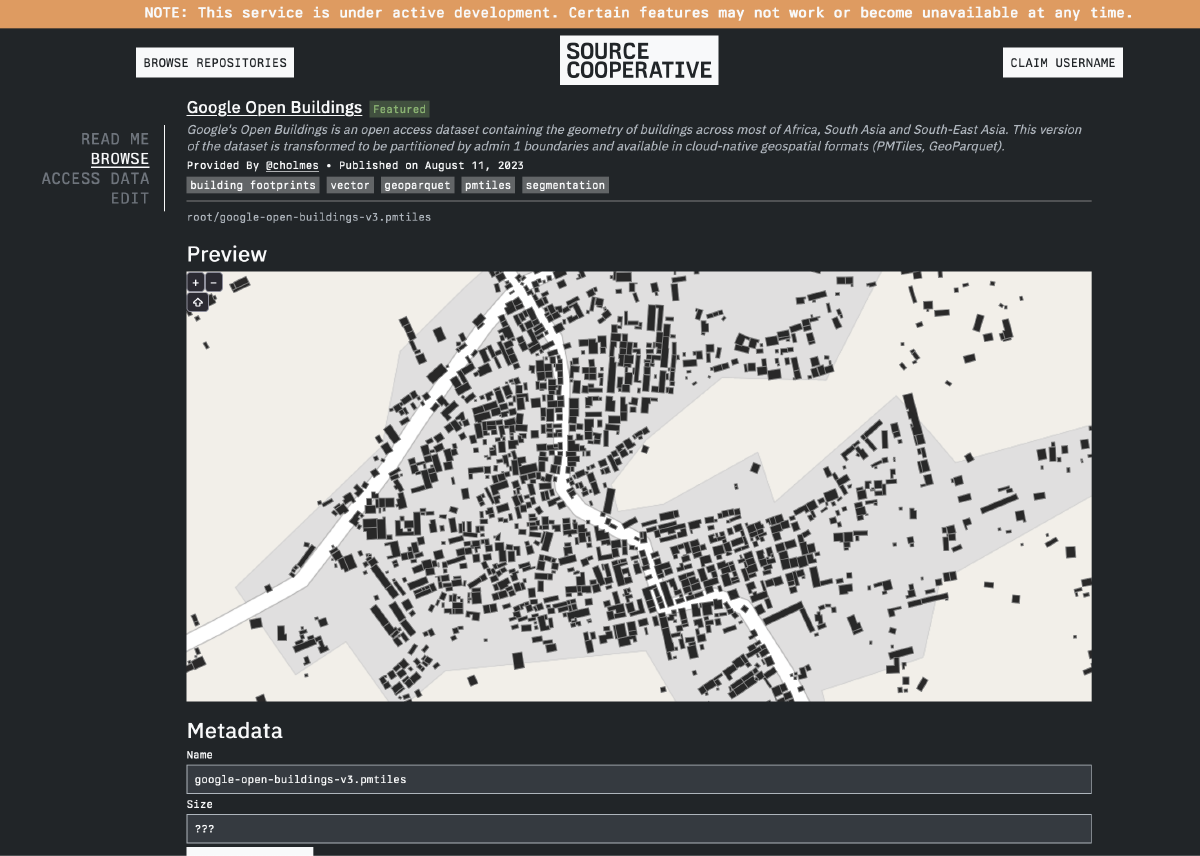
Example of a PMTiles viewer in Source
Right now, if you click on an individual file within Source’s file browser, your web browser will attempt to download it. We are working on a feature that will instead show you a preview of the file along with any relevant metadata we have about it if you navigate to an individual file. At that point you will be able to decide if you want to download it. In the screenshot above, you can see what this might look like for a PMTiles file.
(Update: we added basic individual file preview functionality fpr PMTiles on 16 Oct 2023. You can see it in action on any PMTiles file on Source, such as this one.)
We plan to prioritize previews for Cloud-optimized GeoTIFFs, GeoJSON files, and Zarr data (thanks to support from Columbia University’s Lamont-Doherty Earth Observatory).
As we open up the code behind Source, this is a feature that will benefit from community input. As our members need to add preview functionality for new file formats, they will be able to propose their own solutions.
Restricted access repositories
Not all data should be open and we will allow data providers to restrict access to their data products. Access to data will be controlled at the repository level and will be limited to Source members that data providers have explicitly allowed to access data by adding their email addresses to an “allow list.” Based on member needs, we may allow creation of more sophisticated access management policies.
Charging for access to repositories
Data providers should be able to charge for access to their repositories. Our initial plan is to allow data providers to charge a monthly subscription fee to enable access to their data products.
Usage analytics
We should provide data providers with information on how frequently their repositories are visited, how much of their data has been accessed, and information about who is accessing their data (as permissible by law).
Anyone visiting Source should also have some insight into the usage of data products in order to determine which data products have proven value by being frequently accessed.
Self-service organizational profile creation
If you want to create a profile for an organization, you currently have to email us. Source members should be able to do this on their own.
Markdown editing in browser
Members should be able to edit their README.md files within their web browser and see a preview of how it will be rendered.
Advanced Markdown support
We are currently exploring variations of Markdown such as QMD or MyST that will allow members to provide interactive README files that include data visualizations.
Actions
Similar to GitHub Actions, we want to allow members to run workflows on data published on Source. A first example of an Action we want to enable is to run data linters to ensure that data adheres to certain schema or standards (e.g. validating a STAC catalog). This may be extended to performing transformations on data, such as converting a corpus of CSVs into Parquet.
API to write data
Getting credentials to write data into Source is currently a manual process. We will develop APIs that allow members to create automated processes to create repositories and add data to repositories.
Bring your own bucket
If members are hosting their data in a compatible object store, we will allow them to “register” their data on Source, giving it a listing available on a Source URL, but with the underlying data being served from their own infrastructure.
Pangeo Forge integration
Pangeo Forge users should be able to publish data directly to Source and any Source repository created by Pangeo Forge should link back to Pangeo Forge to indicate the repository’s provenance.
More repository metadata
We should gather as much metadata (e.g. schema.org and Croissant) as we can about repositories and make it available to search engine or machine learning crawlers.
Storing and displaying object checksums
We should display a checksum for every object stored in Source.
Push notifications for updates to repositories
It should be possible to subscribe to push notifications of updates to repositories, including notifications about objects that have been added to repositories and notifications about existing objects that have been updated.
Moving Faster
Source has been made possible through support from NASA, Columbia University’s Lamont-Doherty Earth Observatory, AWS, Microsoft, Schmidt Futures, and the Bill & Melinda Gates Foundation. If you’re interested in funding us to help us move faster and create a new kind of technology provider, please write us at hello@source.coop. Let us know if you’d like to fund any of the features listed above or if you have other ideas of how you can help us make it easier to publish data on the web.